What can we do to improve the engine we made in the last blog, the most obvious thing we can improve is search, there exists a lot of searching algorithms out there, but generally Minimax is the tea of the discussion, tho using it alone is insanely inefficient, just fully traversing depth 5 from initial chess position would take about 5M nodes, we can reduce this down to an insanely low 100K using Alpha-Beta method and others like MTD(f)
Also our engine should get a sense of how much time is left and make decisions based on that, also we'll make lots of other stuff to enhance our engine!
Alpha-Beta? What's that?
i fear im a horrible teacher for such a new concept, i suggest you watch this video, it really made me understand it! it's easy don't get scared!
Quiescence Search: Stop making stupid moves!
there is a thing called Horizon Effect, which is basically that, in a fixed depth, evaluation functions might consider a really bad board in 1 or 2 moves as an alright or even good one!
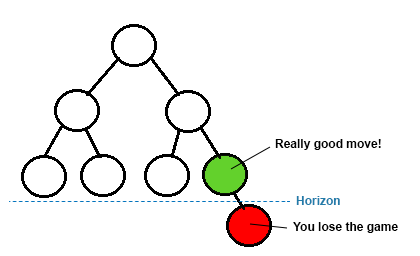
to fix this, we can use Quiescence Search, it's basically traversing the nodes while there is a capturing move, this stops the engine from making stupid moves but it's kinda costly, so you can perhaps ignore pawn captures, it depends on how much are you willing to pay for a non-stupid engine!
int quiescence(bool turn, int alpha, int beta) {
int bs = evaluate();
if(turn) {
if(bs >= beta) return beta;
alpha = max(alpha, bs);
}
else {
if(bs <= alpha) return alpha;
beta = min(beta, bs);
}
movegen(turn);
vector<CMove> local(Moves, Moves + mvs);
for(int i = 0 ; i < local.size() ; i++) {
if(local[i].capture == EMP) continue;
domove(local[i], 1);
int ls = quiescence(turn^1, alpha, beta);
undomove();
if(turn) {
alpha = max(alpha, ls);
if(alpha >= beta) return alpha;
}
else {
beta = min(beta, ls);
if(beta <= alpha) return beta;
}
}
return bs;
}Move ordering
when doing Alpha-Beta notice that the better the first move the more likely it is for a alpha/beta-cutoff, so if we can attempt to sort the moves from best to worst, we'll have more chances for an earlier alpha-beta cutoff
there exists a lot of Move ordering heuristics, but since we're not making the next stockfish we can use something simple like MVV-LVA, which basically sorting by capturing value, it makes sense that capturing a queen is better than moving a pawn! there exists other ones such as Killer, MVV-LVA would look something like:
std::sort(local.rbegin(), local.rend(), [&](CMove a, CMove b) {
return val[a.capture] < val[b.capture];
});Killer move is also widely used
Iterative deepening
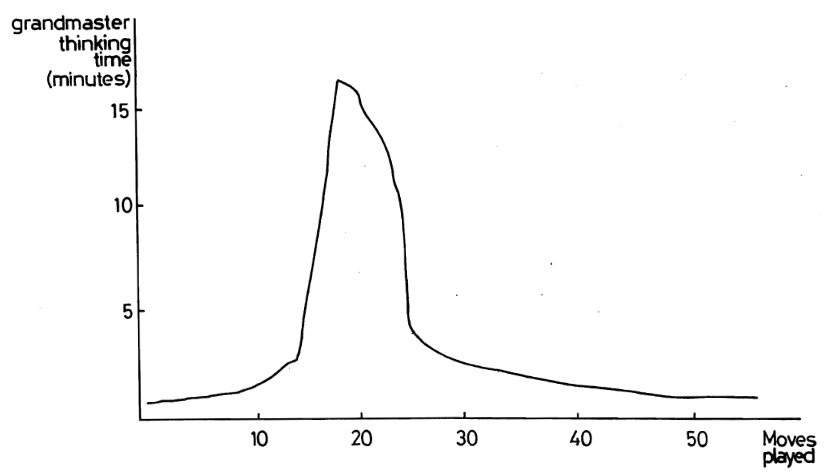
This is basically doing BFS in the search tree while actually doing DFS, the idea is basically to do a fixed depth Minimax each time while increasing depth limit, until we pass some time or some depth perhaps.
The reason why this is not insanely slow is since, on average, we have that $\text{nodes at depth n} = 25 \times \text{nodes at depth n-1}$ so this stays at a time complexity of $O(b^n)$ same as normal Minimax.
And the reason why someone might want to do this is since engines have to worry about time too, you shouldn't traverse 30s worth of nodes while you have 10s on the clock, but it introduces a challenge of time management that we didn't worry about before, when should an engine spend time?
Time management
This is a question of "how much time should my engine spend in this position considering the time he still has"
The straight-forward strategy is to just take expected number of moves in a chess game (should be around 31) and spend $\text{time left} / \text{expected}$ per move, but this is not good! some boards require more thinking than other, generally the middle game does require more time than the endgame.
One strategy, which is the one i'll be using, is to consider a variable $stab$, how much time the best move changes during Iterative deepening, if the engine is so sure about a move, $stab$ should be $0$ or $1$, and there is no point in searching further depths if the engine is so sure (right?)
so the formula would be: $$\text{time} = \min(\text{game mode max},\text{stab} + \text{time left} / \text{expected}, \text{time left})$$ and we'll only move to the next depth during Iterative deepening if $$\text{time sum from last depths} \times 33 \le \text{time}$$ for 33 being the average growth factor, this is a claim i've made (this time strategy isn't supposed to be good, this is my blog after all i can write wtv)
FEN reading!
FEN is basically a file format that describes a board in a pseudo compressed way, we'll really need it later on in part 3 when training our MLP! (spoilers!)
implementing FEN get's tedious, it's long and goofy, i'll let you have the piece placement part, tho you must implement the other sections for a correct board representation (shouldn't be hard!):
int u = 0, i = 0, c = 1;
for(; i < str.size() ; i++) {
if(str[i] == ' ') break;
if(str[i] == '/') {
u = c << 4;
c++;
continue;
}
if('0' <= str[i] and str[i] <= '9') {
u += str[i] - '0';
continue;
}
cout << u << endl;
if(str[i] == 'p') Board[u] = BP;
else if(str[i] == 'n') Board[u] = BN;
else if(str[i] == 'b') Board[u] = BB;
else if(str[i] == 'r') Board[u] = BR;
else if(str[i] == 'q') Board[u] = BQ;
else if(str[i] == 'k') Board[u] = BK;
else if(str[i] == 'P') Board[u] = WP;
else if(str[i] == 'N') Board[u] = WN;
else if(str[i] == 'B') Board[u] = WB;
else if(str[i] == 'R') Board[u] = WR;
else if(str[i] == 'Q') Board[u] = WQ;
else if(str[i] == 'K') Board[u] = WK;
u++;
}Transposition table
One should notice that during our search, we traverse the same Board a lot of times, if we could've store these boards instead we could improve the speed of the search by a huge factor.
notice that during Alpha-Beta Minimax there are 3 ways to return a result:
- returning exact result
- returning an upper bound (beta cut-off)
- returning a lower bound (alpha cut-off) so we can store these three cases, and yea! i believe this code is readable enough to speak before me:
// transposition table
enum NType {
EXACT = 0,
LOWER = 1,
UPPER = 2
};
struct TB {
int depth;
int val;
CMove BMove;
NType flag;
};
gp_hash_table<u64, TB> ttable;
// retrieving ttable info
bool retrieve_tb(u64 key, int depth, int alpha, int beta, int &act_s, CMove &act_m) {
auto it = ttable.find(key);
if(it == ttable.end()) return 0;
const TB &e = it->second;
act_m = e.BMove;
// flight
if(e.depth < depth) return 0;
int val = e.val;
if(e.flag == EXACT) {
act_s = val;
return 1;
}
if(e.flag == LOWER) {
if (val >= beta) {
act_s = val;
return 1;
}
}
if(e.flag == UPPER) {
if(val <= alpha) {
act_s = val;
return 1;
}
}
return 0;
}
void set_tb(u64 key, int score, int depth, NType flag, CMove Bm) {
TB e;
e.val = score;
e.depth = depth;
e.flag = flag;
e.BMove = Bm;
ttable[key] = e;
}MTD(f): binary search!
MTF(f) is an algorithm made in the late 1990s, the idea is to basically binary search on "is the score of minimax $\ge T$"! it's really nice and can be fast when done right, in code it should look something like this:
// f: first guess
int mtdf(bool turn, int f, int depth) {
int l = -INF;
int r = INF;
while(l < r) {
int beta = f + (f == l);
f = minimax(depth, depth, turn, beta-1, beta);
if(f < beta) r = f;
else l = f;
};
return f;
}for a more formal discussion about it check this article